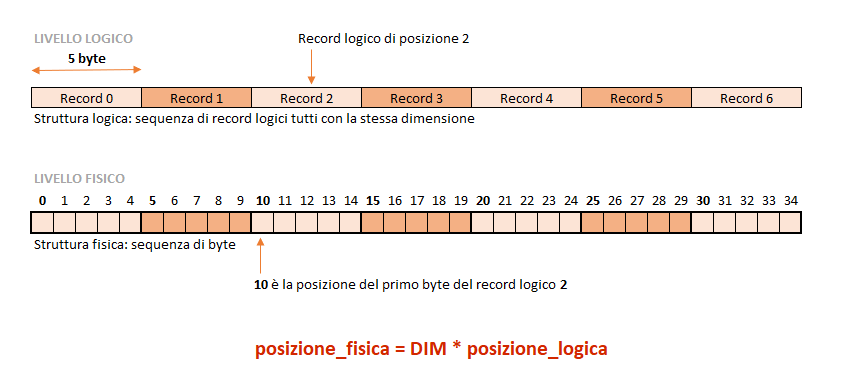
Il file binario è organizzato in record logici tutti della stessa dimensione.
Di conseguenza, conoscendo la posizione logica del record, che parte da 0, è possibile calcolare la posizione del primo byte nella struttura fisica. In questo modo, sfruttando il metodo seek, possiamo impostare la posizione all’interno dello stream ed effettuare la lettura o la scrittura.
Per ottenere una struttura record a dimensione fissa dobbiamo rendere i dati di tipo stringa a dimensione fissa, mentre gli altri tipi, indipendentemente dal valore, hanno una occupazione in byte fissa. Quindi dobbiamo fare delle ipotesi sulla dimensione massima dei campi di tipo stringe e prevedere un carattere riempitivo per raggiungere tale dimensione quando la dimensione reale della stringa sia inferiore.
Inoltre, occorre tenere in considerazione che ci sono codifiche a lunghezza variabile, il che complica la gestione, per cui useremo la codifica ASCII in modo da avere una corrispondenza tra numero di caratteri e numero di byte. Vedremo poi come superare tale limite. Intanto notiamo come questa organizzazione ha un primo limite: si spreca spazio.
Iniziamo a definire la classe Auto che modella il nostro record logico:
class Auto
{
public string Targa { get; set; }
public string Descrizione { get; set; }
public int Km { get; set; }
public float Prezzo { get; set; }
}
Notiamo che in base alla lunghezza della stringa descrizione la dimensione in byte del record logico cambia. Mentre la targa, pur essendo una stringa, è sempre lunga 7 byte, che in ASCII sono 7 byte. Analogamente i km e il prezzo hanno una dimensione fissa pari a 4 byte ciascuno. Se ipotizziamo per la descrizione una dimensione massima di 50 caratteri (che in ASCII sono 50 byte) avremo che il record logico sarà lungo 65 byte.
Il programma che vogliamo sviluppare crea un file binario e salva all’interno una lista di auto. Per la stringa descrizione completeremo la lunghezza a 50 caratteri usando come carattere di riempimento uno spazio.
static void Main(string[] args)
{
string fileName = @"C:\guida_C#\dati.dat";
try
{
List<Auto> auto = new List<Auto>();
auto.Add(new Auto() { Targa = "AX456TA",
Descrizione = "Fiat Punto 1.4",
Prezzo = 13000,
Km = 43789 });
auto.Add(new Auto() { Targa = "CX553SU",
Descrizione = "Fiat Panda 1.0",
Prezzo = 9000,
Km = 33789 });
auto.Add(new Auto() { Targa = "ZX455FH",
Descrizione = "Audi A3",
Prezzo = 18000,
Km = 143789 });
auto.Add(new Auto() { Targa = "CV851GP",
Descrizione = "BMW X3",
Prezzo = 16000,
Km = 563789 });
auto.Add(new Auto() { Targa = "AB159HL",
Descrizione = "BMW X1",
Prezzo = 21000,
Km = 89789 });
auto.Add(new Auto() { Targa = "FV752CF",
Descrizione = "Fiat Tipo 1.4",
Prezzo = 12000,
Km = 56789 });
using (BinaryWriter writer = new BinaryWriter(File.Open(fileName, FileMode.Append)))
{
byte[] buffer = null;
foreach (Auto a in auto)
{
//7 byte
buffer = UnicodeEncoding.ASCII.GetBytes(a.Targa);
writer.Write(buffer);
//50 byte
string d = a.Descrizione.PadRight(50, ' ').Substring(0, 50);
buffer = UnicodeEncoding.ASCII.GetBytes(d);
writer.Write(buffer);
//4 byte
writer.Write(a.Prezzo);
//4 byte
writer.Write(a.Km);
//Il singolo record occupa 65 byte
}
writer.Close();
}
}
catch (Exception ex)
{
Console.WriteLine("Errore: {0}", ex.Message);
}
}
Per accedere ad un record logico nota la posizione del record utilizziamo il seguente codice:
static void Main(string[] args)
{
string fileName = @"C:\guida_C#\dati.dat";
int DIM_REC = 65; //byte
int i = 2; //vogliamo accedere al record 2, cioè la terza auto partendo dal record 0.
try
{
using (BinaryReader reader = new
BinaryReader(File.Open(fileName, FileMode.Open)))
{
int pos = DIM_REC * i; // indirizzo del byte nello stream
reader.BaseStream.Seek(pos, SeekOrigin.Begin);
string targa = ASCIIEncoding.ASCII.GetString(reader.ReadBytes(7));
string descrizione = ASCIIEncoding.ASCII.GetString(reader.ReadBytes(50));
float prezzo = reader.ReadSingle();
float km = reader.ReadInt32();
Console.WriteLine($"Posizione record: {i}");
Console.WriteLine($"Posizione del primo byte: {pos}");
Console.WriteLine($"Targa: {targa}");
Console.WriteLine($"Descrizione: {descrizione}");
Console.WriteLine($"Prezzo: {prezzo}");
Console.WriteLine($"Km: {km}");
reader.Close();
}
}
catch (Exception ex)
{
Console.WriteLine("Errore: {0}", ex.Message);
}
}
che produce in output i seguenti dati corrispondenti alla terza auto (record 2):
Posizione record: 2 Posizione del primo byte: 130 Targa: ZX455FH Descrizione: Audi A3 Prezzo: 18000 Km: 143789
Abbiamo detto che un primo difetto è lo speco di spazio. Però possiamo notare subito un secondo difetto: le ricerche non si eseguono conoscendo la posizione del record logico ma quello di un campo chiave. Un campo si dice chiave quando assume valori univoci, cioè non ci sono record che hanno lo stesso valore del campo chiave. Per rendere efficiente la ricerca occorre che il file sia ordinato in modo da effettuare una ricerca binaria, diversamente siamo obbligati ad eseguire un accesso sequenziale come visto per i file di testo. Sarà oggetto della prossima lezione la gestione di un file binario con record ordinati per un campo chiave.